【转】C++基础知识归纳(1)-大厂必备八股文篇
本文整理自CSDN
C++基础知识归纳(1)-大厂必备八股文篇
const作用
常引用
常对象
常成员函数(调用限制:常对象->常成员函数->常成员函数)
extern和static(作用域限制)
运算符重载
单目运算符重载为?
双目重载为?
=、[]只能重载成员函数,<<、>>只能重载为友元函数。
(主要区别在于是否访问参数对象的private成员)
内存分配方式
栈、
堆、
全局静态区、
常量区、
代码区
全局变量和全局静态变量区别
new delete 与malloc free
同:申请堆空间,成对使用(否则内存泄漏/二次释放)
异:主要是new和delete除了分配空间、释放空间外,还分别调用类的构造、析构函数,但malloc free不会。
其次malloc 还可以通过realloc重新分配内存,new不能;new是运算符,malloc是函数。
explicit
避免函数参数被隐式类型转换, explicit关键字只对有一个参数的类构造函数有效
mutable
和const相反,mutable变量永远可变,高于const优先级,即使在const函数中。(使用mutable修饰的数据成员可以被const成员函数修改)
const修饰函数的返回值
该返回值只能被赋给加const修饰的同类型指针
1 | const char * GetString(void); |
宏、const和enum
对于#define 定义的:
1.常量:使用enum和const代替;
2.宏函数,使用内联函数代替。
stack的生存期
static对象寿命?
local static对象、non-local static对象是什么?两者生命周期?
(local static对象包括作用域内、函数内对象)
STL相关
***************学习***************
STL是C++通用库,由**,____,____,____,**构成。
顺序容器:vector、deque、list、forward_list、array、string、
关联容器:map、multimap、set、multiset
容器适配器:priority_queue(基于vector)、queue(基于deque)、stack(基于deque) 其他:bitset
- vector和deque如果没有预先指定大小,是不能用下标法插入元素的!
- 序列式容器才可以在容器初始化的时候制定大小,关联式容器不行;
- 关联容器的迭代器不支持it+n操作,仅支持it++操作。
算法相关头文件<algorithm>,<numeric>
迭代器几种?输入型迭代器(只读、自增),输出型迭代器(只写、自增),前向迭代器(前两者结合、自增),双向迭代器(读写、自增自减),随机存取迭代器(还支持比较、+-+=-=、迭代器减法、下标乱序访问)
https://blog.csdn.net/sim_szm/article/details/8980879
仿函数是什么?仅实现一个()运算符重载函数的空类,实现函数效果
适配器几种?容器适配器、迭代器适配器、函数适配器(基础容器并不是固定的,可以选择)
空间配置器分几级?
程序编译
预处理 -> 编译 -> 汇编 -> 链接
https://blog.csdn.net/daaikuaichuan/article/details/89060957
- 预处理:对宏定义进行展开,不进行语法检查(常量建议用const或enum,函数用内联函数)
- 编译:源文件翻译成二进制目标代码生成汇编代码.s文件,这个过程检查语法错误
- 汇编:根据汇编代码生成目标文件.o或.obj文件,这个过程把汇编语言代码翻译成目标机器指令
- 连接:将目标文件和其他文件分别进行编译生成的目标程序模块、系统提供的标准库函数链接在一起,生成可执行文件.out或.exe文件。分为静态连接和动态链接
const 赋值类型不一致时,生成新的常量
?
单例模式示例
位运算
左移右移补什么?(左移补0,右移,有符号补符号位,无符号补0)
负数存储什么形式?(计算机存储补码,正数原码反码补码相同,负数补码为反码+1)
C++二维数组作为形参传递参数(三种方式)
数组:形参是数组,给出第二维;void fun1(int array[][10])
引用:形参是二维数组的引用,必须加括号,给定二个维度;void fun2(int (&array)[10][10])
这两种都是传递实参名字。fun1(array);
指针:形参是二维指针、第二维。void fun3(int **a, int n);
int *a[n];
for(int i=0;i<n; i++) a[i] = new int [n];
实参fun3(a,n);
全局变量和static变量的区别
同:
异:
都是静态存储、都存在全局静态区,区别在文件作用域。
全局变量本身就是静态存储方式, 静态全局变量当然也是静态存储方式。 这两者在存储方式上并无不同。这两者的区别在于非静态全局变量的作用域是整个源程序, 当一个源程序由多个源文件组成时,非静态的全局变量在各个源文件中都是有效的。 而静态全局变量则限制了其作用域, 即只在定义该变量的源文件内有效, 在同一源程序的其它源文件中不能使用它。由于静态全局变量的作用域局限于一个源文件内,只能为该源文件内的函数公用, 因此可以避免在其它源文件中引起错误。
为什么栈要比堆速度要快
定位 (栈FILO,找到数据更快)
指令 (栈有CPU提供指令支持,操作系统支持的堆数据)
缓存 (栈一级缓存、堆在二级缓存,硬件性能上有差别)
优化 (各语言对栈的优化支持要优于对堆的支持,)
c++ 析构函数调用时间
3条,需要注意的是:
对象i是对象o的成员,o的析构函数被调用时,对象i的析构函数也被调用
定义了对象的函数调用结束、局部对象释放、全局对象释放、new创建的对象释放、对象析构时,其成员函数也调用析构
c++中关于cout与printf的简单区别
3条区别
原理:cout使用流,存在缓冲区,只有当缓冲区满或者遇到endl、调用flush才输出
printf无缓冲输出。
效率:原理上流操作效率更高,但是____,总体效率更低
class与struct区别
默认继承权限
成员的默认访问权限
“class”这个关键字还用于定义模板参数,就像“typename”。但关建字“struct”不用于定义模板参数
静态绑定 动态绑定 (也叫动态连编,静态连编)
多态只能在运行时确定调用哪个方法
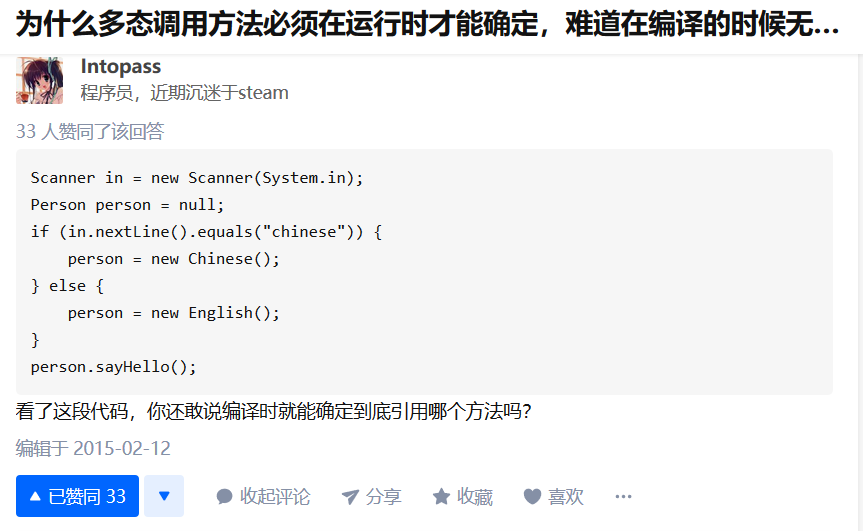
C/C++中指针和引用的区别
类型 指针有类型是变量、有内存;引用无类型不是变量、无内存。
大小 指针大小4或8字节;引用是被引用对象的大小。
初始化 指针初始化可选(一般赋值或置NULL),引用必须初始化赋值。
const 有const指针,没有const引用
可变 指针在使用中可以指向其它对象,但是引用只能是一个对象的引用
多级 指针可以有多级指针(**p),而引用只有一级
为什么要有引用?运算符重载
为什么要有指针?历史遗留的兼容性问题
它们的联系?引用底层使用指针实现
c++里面的四种智能指针以及代码实现
为什么要有智能指针?
auto_ptr(c++98的方案,cpp11已经抛弃) 特点、被废弃原因 (所有权)
unique_ptr(替换auto_ptr) 特点、与auto_ptr异同 (独占所有权)
shared_ptr 为什么要有? 特点、与unique_ptr异同、机制 (共享所有权)
weak_ptr 为什么要有?特点、和引用计数的关系 (仅指向shared_ptr、不增加引用计数)
虚函数和多态
静态多态(重载)和动态多态
父类加了virtual,子类重写还用加吗?
类的最开始存放虚函数表指针,占4/8字节,继承时也会继承父类虚函数表。
虚函数表中存放父类的虚函数地址,若子类重写,则会替换对应函数地址。
extern “C”的主要作用简单解释
加上extern “C”后,会指示编译器这部分代码按C语言(而不是C++)的方式进行编译。
区别:编译时一个只有函数名、一个还包括参数类型。
请你说说C语言是怎么进行函数调用的
压栈内容的顺序?
C语言函数参数压栈顺序?
C++中拷贝赋值函数的形参能否进行值传递?
提示:值传递在实参传递时拷贝
include头文件的顺序以及双引号””和尖括号<>的区别
当前头文件目录
编译器设置的头文件路径(编译器可使用-I显式指定搜索路径)
系统变量CPLUS_INCLUDE_PATH/C_INCLUDE_PATH指定的头文件路径
使用尖括号包含的头文件不会查找”当前头文件目录”
面试题—>#include尖括号和双引号的区别?
#include<> ,从标准库中寻找头文件。
#include””,从当前目录开始寻找头文件。
STL中迭代器有什么作用作用,有指针为何还要迭代器
聚合对象的模式
一个C++源文件从文本到可执行文件经历的过程
预处理 -> 编译 -> 汇编 -> 链接
https://blog.csdn.net/daaikuaichuan/article/details/89060957
预处理:对宏定义进行展开,不进行语法检查(常量建议用const或enum,函数用内联函数)
编译:源文件翻译成二进制目标代码生成汇编代码.s文件,这个过程检查语法错误
汇编:根据汇编代码生成目标文件.o或.obj文件,这个过程把汇编语言代码翻译成目标机器指令
连接:将目标文件和其他文件分别进行编译生成的目标程序模块、系统提供的标准库函数链接在一起,生成可执行文件.out或.exe文件。分为静态连接和动态链接
内存泄漏原因和判断方法
原因:
方法:linux下命令valgrid、编码习惯、链表形式管理指针、智能指针、插件(Dmalloc等)
分类:
new和malloc的区别
分配依据(数据类型/指定大小)
返回类型(对象指针、void*)
构造函数(new除了分配内存,还会调用构造函数)
类型(new是运算符、可重载;malloc是函数)
扩容(malloc申请到的内存可realloc扩容)
失败返回值(分配失败,new抛出bad_malloc的异常,malloc返回NULL)
申请数组(new[] delete[];malloc申请连续内存)
段错误
1.段错误是什么
访问的内存超出了系统给这个程序所设定的内存空间
2.段错误原因——4个
不存在的、系统保护的、只读的、栈溢出
C++重载实现原理
依据什么区分函数?()
重载时函数可以哪些不同?
C++ 函数调用过程
哪三步
sizeof求类型大小
哪些数据之和(非静态成员数据的类型大小之和)
class大小怎么计算?类似struct
字节对齐原则:
在系统默认的对齐方式下,每个成员相对于这个结构体变量地址的偏移量正好是该成员类型所占字节的整数倍,且最终占用字节数为成员类型中最大占用字节数的整数倍。
1 | struct A { |
总结:
- 最终大小一定是最大数据类型的整数倍;
- 静态变量不占空间
- 每种类型的偏移量为自身的n倍;
如何调试c++ 多线程程序?
https://blog.csdn.net/zhangye3017/article/details/80382496
info threads
thread ID(1,2,3…)
面向对象和面向过程的区别
面向对象:三大特性、五大原则。划分成各个____
面向过程:自__向__顺序、____形结构。划分成各个____
(过程)优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗源;比如嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。缺点:没有面向对象易维护、易复用、易扩展。
(对象)优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统。缺点:性能比面向过程低。
关于引用赋值的多态
通过父类的____指向子类对象来实现多态
1 | Class B; |
模板的声明和实现不能分开的原因
?????????????
C++类中引用成员和常量成员的初始化(初始化列表)
哪些变量初始化必须要初始化列表
(注意区分赋值和初始化)
枚举变量和宏的区别(3种常量区别)
- 内存
const常量拷贝数量?
#define常量拷贝数? 有多少展开多少,不分配内存
- 效率
const常量在符号表,而不是存储空间中,不用读写内存,效率高;
- 编译器处理方式
- 类型和安全检查
- 存储方式
枚举和宏
是否是常量
枚举常量属于常量,宏不是
是否有类型
枚举有类型,宏没有类型
是否有检查,易错性
宏替换没有检查,
定义常量的数量
枚举可以一次定义多个,宏智能一个
枚举和宏作用时间和存储形式不同
宏不分配内存
memset为int型数组初始化问题
头文件:#include <string.h>
char数组可以设置任意值
int数组只能设置0和-1,因为其实是把value转换成的16进制数字写入内存。
void * memset( void * ptr, int value, size_t num );
直接向int数组赋值1,底层存储的数据为0x01010101,对应十进制数并不是1
bzero区别?
C++中volatile的作用
为什么要有?使用场景?
建议编译器不要对该变量进行优化
你希望这个值被正确的处理,每次从内存中去读这个值,而不是因编译器优化从缓存的地方读取(比如读取缓存在寄存器中的数值),,从而保证volatile变量被正确的读取。
编译器对 inline 函数的处理步骤
步骤?(复制函数体、局部变量、参数映射、返回值)
优缺点
虚函数(virtual)可以是内联函数(inline)吗?
可以,但在多态时不行。
内联函数在____阶段将函数展开,而虚函数在运行期才能确定具体调用哪个。
const * 和 *const区别
const 在左边表示修饰数据类型,在右边表示修饰指针。
自我赋值可能带来的危害有哪些?
“自我赋值安全性”问题
“异常安全性”问题
右值引用
一般的引用是左值,但新标准引入了新的引用类型——右值引用&&
除了右值引用&&,const左值引用也可以绑定右值
1 | int i = 42; |
左值和右值
左值引用
右值引用
常量左值:使用 const T&, 既可以绑定左值又可以绑定右值
已命名的右值引用,编译器会认为是个左值
- str6 = std::move(str2),虽然将str2的资源给了str6,但是str2并没有立刻析构,只有在str2离开了自己的作用域的时候才会析构,所以,如果继续使用str2的m_data变量,可能会发生意想不到的错误。
- 没有提供移动构造函数,只提供了拷贝构造函数
- move对含有资源的对象更有意义。(why)
universal references(通用引用)
T&&是左值还是右值引用?
完美转发
所谓转发,就是通过一个函数将参数继续转交给另一个函数进行处理,原参数可能是右值,可能是左值,如果还能继续保持参数的原有特征,那么它就是完美的。
1 |
|
总结
- 三种引用类型,左值引用、右值引用和通用引用。通用引用由初始化时绑定的值的类型确定
- 引用折叠规则:所有的右值引用叠加到右值引用上仍然是一个右值引用,其他引用折叠都为左值引用。当T&&为模板参数时,输入左值,它将变成左值引用,输入右值则变成具名的右值应用。
- 移动语义可以减少无谓的内存拷贝,要想实现移动语义,需要实现移动构造函数和移动赋值函数。
- std::move()将一个左值转换成一个右值,强制使用移动拷贝和赋值函数,这个函数本身并没有对这个左值什么特殊操作。
- std::forward()和universal references通用引用共同实现完美转发。
补充:
动态库、静态库区别:
后缀:静态库.lib,动态库.dll。(静态库.a,动态库.so)
one is library archive and other is shared object
包含方式:静态库中代码被放入可执行文件中,会使文件大小更大;而动态库文件是单独的文件。动态库可执行程序文件更小
//加载时机:无论静态库中代码是否用到,都会在程序运行时被加载;动态库文件只有在需要时才被加载。动态库更节省空间
加载数量:运行多个程序,内存中会存在多份静态库文件的拷贝,分别存在每个程序的空间。如果是动态库,那么永远只会有一份拷贝。动态库更节省空间
依赖:只要发布者的lib文件正确,用户打开静态链接的可执行文件即可用,没有依赖;动态链接生成的文件需要依赖.dll文件才能运行,并且dll要和可执行程序兼容,否则也不会运行。
链接分为两种:静态链接、动态链接。
1)静态链接
静态链接:由链接器在链接时将库的内容加入到可执行程序中。
优点:
- 对运行环境的依赖性较小,具有较好的兼容性
缺点:
- 生成的程序比较大,需要更多的系统资源,在装入内存时会消耗更多的时间
- 库函数有了更新,必须重新编译应用程序
2)动态链接
动态链接:连接器在链接时仅仅建立与所需库函数的之间的链接关系,在程序运行时才将所需资源调入可执行程序。
优点:
- 在需要的时候才会调入对应的资源函数
- 简化程序的升级;有着较小的程序体积
- 实现进程之间的资源共享(避免重复拷贝)
缺点:
- 依赖动态库,不能独立运行
- 动态库依赖版本问题严重
3)静态、动态编译对比
前面我们编写的应用程序大量用到了标准库函数,系统默认采用动态链接的方式进行编译程序,若想采用静态编译,加入-static参数。
结构体内存对齐、结构体大小
总结:
- 最终大小一定是最大数据类型的整数倍;
- 静态变量不占空间
- 每种类型的偏移量为自身的n倍;
对象大小
没有成员变量、没有虚函数时最小,为1,单纯占位符,无实际意义
有成员变量,考虑基类大小、内存对齐
主要考虑如下:
- 内存对齐
- 基类大小
- 静态成员(不算入大小,而是存在于堆当中)
- 虚函数表指针
- 虚基类表指针
const能否修饰static函数和成员、构造函数、析构函数、虚函数
const可以修饰static成员,但不能修饰static函数(static函数属于类,没有this指针,而const阻止修改对象的数据成员)
构造或析构函数不允许const,虚函数允许const
函数指针好处、用途
(https://blog.csdn.net/wujiangguizhen/article/details/17153495)
一般的时候用不到,主要还是一个简化结构和程序通用性的问题
1.实现回调函数,更加灵活
如果函数作参数不用指针的话,还真不知道怎么解决。参数传递一般就是传值和传址两种方式,作为函数的话,好像都想不出怎么传值。
- 如libcurl中的函数:
1 | curl_easy_setopt(curl_handle, CURLOPT_WRITEFUNCTION, write_memory_callback); |
一旦收到需要保存的数据,libcurl就会调用此回调函数。 对于大多数传输,此回调被多次调用,每次调用都会传递另一块数据。
- 如qsort函数中,可以自己写比较函数并设置其函数指针为参数,指定对象谁大谁小、升序还是降序
- Libevent中设置回调函数evhttp_set_cb();
- 实现一种多态性
只需要改改指向的对象,就可以操作不同的函数
int a[5];(&a + 1) 与 (a + 1)的区别、a和&a的区别
(https://www.nowcoder.com/questionTerminal/c4e82d13a1684119841b8934ef838847
a和&a数值相同,但a是首元素地址、&a是数组地址,(&a + 1) 与 (a + 1)不同)
指针数组和数组指针
int a[2][3];
a的类型是? (a是指向存放有3个空间数组的指针,等价于int (*p)[3])
1 | int a[2][3]; |
访问二维数组中元素的几种方法?
https://www.nowcoder.com/questionTerminal/0a16d61875e144208e581ee68765bd95
运算符优先级:淡云一笔,鞍落三服。
(https://www.nowcoder.com/questionTerminal/ea83ecd103ac4928bbf4702df42fa2f3)
MySQL高频面试
(https://www.nowcoder.com/discuss/637486?source_id=profile_create_nctrack&channel=-1)
优秀简历模板及计算机网络八股文
(https://www.nowcoder.com/discuss/682094?channel=666&source_id=feed_index_nctrack)
MVC是什么
MVC的全名是Model View Controller,是一种使用“模型-视图-控制器”设计创建Web应用程序的模式,同时提供了对HTML、CSS和JavaScript的完全控制,它是一种软件设计典范。
派生类型和访问权限
(https://www.cnblogs.com/lomper/p/4104542.html)
| **基类成员访问权限(列) ** | public | public | protected | protected | private | private |
|---|---|---|---|---|---|---|
| 派生方式(行) | 派生类对象 | 派生类类内 | **派生类对象 ** | **派生类类内 ** | **派生类对象 ** | **派生类类内 ** |
| public | 可访/可修 | 权限:**public **可访/可修 | 不可访/不可修 | 权限:****protected ****可访/不可修 | 不****可访/不可修 | 权限:*private 不可访*/不可修 |
| protected | 不****可访/不可修 | 权限:protected 可访/不可修 | 不****可访/不可修 | 权限:**private **可访/不可修 | 不****可访/不可修 | 权限:**private **不可访/不可修 |
| private | 不****可访/不可修 | 权限:**private **可访/不可修 | 不****可访/不可修 | 权限:**private **可访/不可修 | 不****可访/不可修 | 权限:*private 不可访*/不可修 |
不能重载的运算符
绝大部分都可以重载,不能重载的只有5个。
- sizeof运算符
- 三目运算符?:
- 类属关系运算符.
- 作用域运算符::
- 指向类成员的指针的运算符.*
其他的,包括箭头运算符-> 类型转换运算符() 左移右移运算符<<>> 等都可以被重载
=、[]只能重载成员函数,<<、>>只能重载为友元函数。
线程异常是否会导致进程结束
内存对齐和地址偏移
要注意区分,内存对齐并不影响其中个元素的大小
https://www.nowcoder.com/questionTerminal/8e8b73ee8f3a402ba47876f8e0b2b62d
#pragma pack指令可以用来调整编译器的默认对齐方式,将会按照n个字节进行对齐。
但是需要注意的是,按照n个字节对齐并非是每个数据都必须是n个字节。每个成员还是按照自己的方式对齐,只不过对齐时从对齐参数(通常是该类型的大小)和n中取较小的那个。
https://blog.csdn.net/czc1997/article/details/81090740
继承关系中的生成顺序
C++构造函数按下列顺序被调用:
(1)任何虚拟基类的构造函数按照它们被继承的顺序构造;
(2)任何非虚拟基类的构造函数按照它们被继承的顺序构造;
(3)任何成员对象的构造函数按照它们声明的顺序调用;
(4)类自己的构造函数。
父类对象成员 -> 父类构造 -> 子类对象成员 -> 子类构造
析构完全相反:
子类析构 -> 子类对象成员 -> 父类析构 -> 父类对象成员

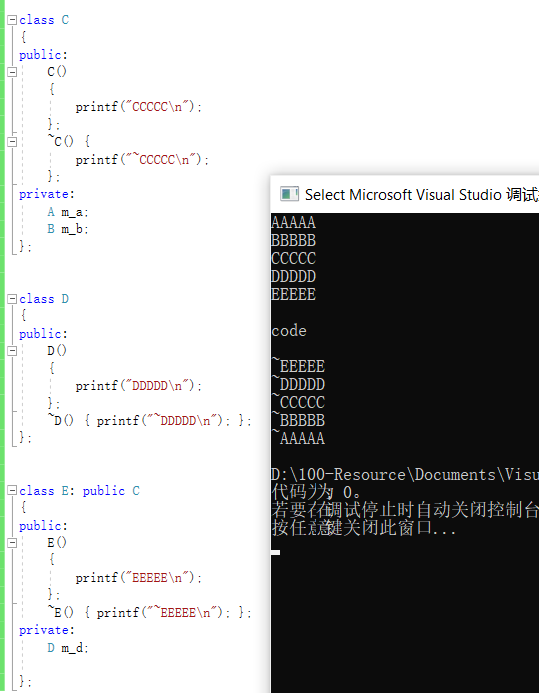
1 |
|
并且,各个成员对象按照声明的顺序依次执行其构造函数(如果类C中对象成员顺序改为B A,构造时的输出也会变成bacde)
bzero和memset
https://blog.csdn.net/weixin_42235488/article/details/80589583
bzero相当于全置0的memset,只有两个参数,适用于char和int
优点:便于记忆《UNIX网络编程 卷一》
但是memset还支持设置其他值
memset怎么设置char数组,怎么设置int数组。有什么区别,为什么
for循环中char
char是一个字节(8位)并且有符号,因此其表示范围为-128~127。下面代码会是死循环
1 | for(char i = 0; i < 256; ++i) |
缓存
为什么需要缓存?
cpu运行速率很快,内存的就很慢,所以就需要缓存,缓存分为一级二级三级,越往下优先级越低,成本越低,容量越大
CPU读写速率:
寄存器>一级缓存>二级缓存>三级缓存
栈是在一级缓存里面的,堆是属于二级缓存,所以栈的效率比堆的高(还有cpu支持、查找速度等其他原因)
linux查找
https://www.jb51.net/article/127577.htm
https://www.cnblogs.com/struggle-1216/p/12066969.html
locate
相当于find -name,-r正则,-i不区分大小写,-n #只列举前#个匹配项
- 速度快
- 模糊查找
- 非实时(而是查找数据库)
- 只搜索用户具备 读取和执行权限 的目录,没有权限,即使数据库有内容,也不显示,为了安全
find
实时查找 -name根据名字查,-iname忽略大小写根据名字查,-inum根据inode查,-regex “PATTERN” 正则查找,-perm [/|-]MODE 根据权限查,-type TYPE根据文件类型查
- 速度慢
- 精确
- 实时查找
- 只搜索用户具备 读取和执行权限 的目录
虚表、虚指针
虚表属于类,虚指针属于对象
https://blog.csdn.net/lalu58/article/details/53674461
每个有虚函数的类或者虚继承的子类,编译器都会为它生成一个虚表,表中的每一个元素都指向一个虚函数的地址(虚表是从属于类的)
编译器会为包含虚函数的类加上一个成员变量,是一个指向该虚函数表的指针,虚表指针是从属于对象的,也就是说,如果一个类含有虚表,那么类的每个对象都含有虚表指针
下面介绍了vfptr和vbptr
https://blog.csdn.net/weixin_43891775/article/details/112003915
vfptr:虚函数指针(指向虚函数表vftable),存放指向虚函数的指针。派生类中含有新的(非重载的)虚函数才有vfptr,如果重载基类函数,只会替换掉基类vfptr中的函数。
vbptr:虚基类指针(指向虚基类表vbtable),发生虚继承的派生类才有。
关于虚基类表中的内容:
虚基类表原理与虚函数表类似,不过虚基类表的内容有所不同。表的第一项表示本虚基类的首地址相对于虚基类表指针的偏移a(如果没有vfptr,那么vbptr在最前,就是0;否则偏移就是-4),从第二项开始表示各个基类地址相对于虚基类表指针的偏移b。可以通过该类首地址、a、b计算得到虚基类的地址

对于派生类B的vbptr(第一个vbptr):
该类首地址为0,a为-4,b为24。因此0-(-4)+24 = 28,得到类B的基类A的首地址为28
(例子来源https://blog.csdn.net/weixin_43891775/article/details/112003915)
https://blog.csdn.net/chczy1/article/details/100521615
如果虚继承的子类中没有新的虚函数,那新的虚函数表指针vfptr也将不复存在
常见网络知识面试题(黑马文档)

链路层:设备到设备,包括主机到路由器、路由到路由、路由器到主机
网络层:网络边缘的主机到主机
传输层:端口到端口
应用层:应用到应用
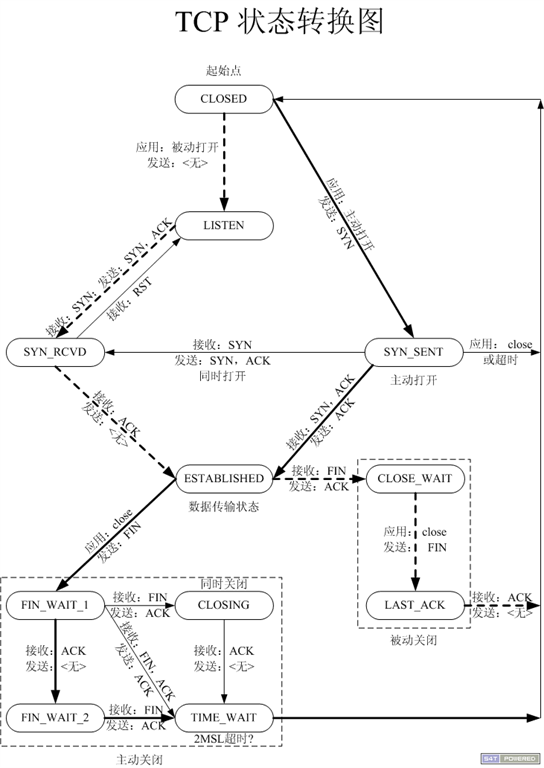
TCP如何建立链接
三次握手。
第一次握手:客户端将标志位SYN置为1,随机产生一个值序列号seq=x,并将该数据包发送给服务端,客户端 进入syn_sent状态,等待服务端确认。
第二次握手:服务端收到数据包后由标志位SYN=1知道客户端请求建立连接,服务端将标志位SYN和 ACK都置为1,ack=x+1,随机产生一个值seq=y,并将该数据包发送给客户端以确认连接请求,服务端进入syn_rcvd状态。
第三次握手:客户端收到确认后检查,如果正确则将标志位ACK为1,ack=y+1,并将该数据包发送给服务端,服务端进行检查如果正确则连接建立成功,客户端和服务端进入established状态,完成三次握手,随后客户端和服务端之间可以开始传输 数据了
TCP如何通信
三次握手之后采用流的方式进行数据传输。
发送端多次执行写操作时,TCP先把这些数据放入TCP缓冲区,当TCP模块真正开始发送数据时,发送缓冲区中这些等待发送的数据可能被封装成一个或者多个TCP报文被发出。因此,应用程序执行的写操作次数和TCP模块发送的TCP报文段个数没有固定的数量关系。具体TCP的数据被客户端怎样接受,取决于长度
TCP如何关闭链接
四次挥手。
一方发送FIN,另一方接受;然后另一方发送FIN,一方接受。最后关闭发起方等待2MSL。 (Maximum Segment Lifetime) 。
什么是滑动窗口
滑动窗口是传输层进行流量控制的一种措施,接收方通过通告发 送方自己的窗口大小,从而控制发送方的发送速度,防止发送方发送速度过快而导致自己被淹没。
接收方回复确认报文时,同时会指明自己的窗口(缓冲区)所剩容量。
什么是半关闭
当TCP链接中A发送FIN请求关闭,B端回应ACK后(A端进入FIN_WAIT_2状态),B没有立即发送FIN给A时,A方处在半链接状态,此时A可以接收B发送的数据,但是A已不能再向B发送数据。
1
2
3
4
5
6
7
8
int shutdown(int sockfd, int how);
sockfd: 需要关闭的socket的描述符
how: 允许为shutdown操作选择以下几种方式:
SHUT_RD(0): 关闭sockfd上的读功能,此选项将不允许sockfd进行读操作。
该套接字不再接收数据,任何当前在套接字接受缓冲区的数据将被无声的丢弃掉。
SHUT_WR(1): 关闭sockfd的写功能,此选项将不允许sockfd进行写操作。进程不能在对此套接字发出写操作。
SHUT_RDWR(2): 关闭sockfd的读写功能。相当于调用shutdown两次:首先是以SHUT_RD,然后以SHUT_WR。局域网内两台机器如何利用TCP/IP通信
internet上两台主机如何进行通信
如何在internet上识别唯一一个进程
答:通过“IP地址+端口号”来区分不同的服务
为什么说TCP是可靠的链接,UDP不可靠
TCP:面向连接、字节流、可靠传输。可靠传输主要依靠发送应答机制;超时重传、拥塞控制;重排后交付给上层
UDP:无连接、报文、不可靠。不提供数据确认和超时重传,需要上层协议自己定义。
路由器和交换机的区别
点到点,端到端
https://blog.csdn.net/qq_34940959/article/details/78583993
数据传输的可靠性是通过数据链路层和网络层的点对点和传输层的端对端保证的。端到端与点到点是针对网络中传输的两端设备间的关系而言的。
http状态码
http状态码由三位数字组成,第一个数字代表响应的类别,有五种分类:
\1. 1xx 指示信息–表示请求已接收,继续处理
\2. 2xx 成功–表示请求已被成功接收、理解、接受
\3. 3xx 重定向–要完成请求必须进行更进一步的操作
\4. 4xx 客户端错误–请求有语法错误或请求无法实现
\5. 5xx 服务器端错误–服务器未能实现合法的请求
常见的状态码如下:
- 200 OK 客户端请求成功
- 301 Moved Permanently 永久重定向
- 302 暂时重定向
- 400 Bad Request 客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
- 403 Forbidden 服务器收到请求,但是拒绝提供服务
- 404 Not Found 请求资源不存在,eg:输入了错误的URL
- 500 Internal Server Error 服务器发生不可预期的错误
- 503 Server Unavailable 服务器当前不能处理客户端的请求,一段时间后可能恢复正常
常见错误码: 301:永久重定向 302:临时重定向 304:资源没修改,用之前缓存就行 400:客户端请求的报文有错误 403:表示服务器禁止访问资源 404:表示请求的资源在服务器上不存在或未找到
大端/小端
https://blog.csdn.net/weixin_30786813/article/details/112665201
1 | #include<stdio.h> |
下面表示整数1在计算机中存储的内容:
| 0x00 | 0x00 | 0x00 | 0x01 |
|---|
取地址转换为char指针后再取值,判断低位地址的数据
如果是1,说明低地址存放数据低位,即为小端;否则为大端。
进程
五态模型中,进程分为新建态、终止态,运行态,就绪态,阻塞态。
命令
1 | ps #ps -aux |
获取进程id
1 |
|
进程相关函数
1 | pid_t fork(void); |
父子进程各自的地址空间是独立的
父子进程关系
读时共享、写时拷贝
gdb调试多进程
1 | 一定要在fork函数调用前设置。 |
父进程运行结束,但子进程还在运行(未运行结束)的子进程就称为孤儿进程(Orphan Process)。
孤儿进程没有什么危害,会被系统0号进程(init 进程)收养。
进程终止,父进程尚未回收,子进程残留资源(PCB)存放于内核中,变成僵尸(Zombie)进程。
危害:资源被占用、进程号无法再次被使用。
进程之间私有和共享的资源
私有:地址空间、堆、全局变量、栈、寄存器
共享:代码段,公共数据,进程目录,进程 ID
进程间通信
https://www.cnblogs.com/xuanyuan/p/15078280.html
进程间通信主要是为了数据交换
管道(半双工)
无名管道pipe
流式(约定大小)、具有公共祖先的进程之间才能使用、存在内存中、缓冲区有限
有名管道FIFO
以FIFO格式存在于文件系统中,但内容在内存、有名、非亲缘关系进程可以通信、严格FIFO不支持lseek等定位、缓冲区有限
信号
比如按下ctrl+c结束进程,就是通过SIGINT信号终止程序。
程序中可以通过使用
signal函数捕捉信号。只能作为通知使用,没办法传输数据。信号量
可以用来控制多个线程对共享资源的访问,但信号量有限
PV 原语是对信号量的操作,一次 P 操作使信号量减1,一次 V 操作使信号量加1。
信号量主要用于进程或线程间的同步和互斥这两种典型情况。
信号量数据类型为:sem_t。
共享内存
使一个磁盘文件与存储空间中的一个缓冲区相映射,于是当从缓冲区中取/存数据,就相当于读/写文件中的相应字节。这种方式效率高,尤其是用于共享大量数据时。无须复制,方便快捷
套接字
主要用于不同主机之间的网络通信,全双工。一台主机两个进程间也可以通过本地回环通信,此时不走网卡,不走物理设备,但是走虚拟设备。https://blog.csdn.net/weiyuefei/article/details/78796781
消息队列
内核中的一个消息链表,按照消息块组织,而不是管道中的二进制数据流,并通过系统调用函数来实现消息发送和接收之间的同步。还可以指定数据类型。
缺点:信息的复制需要额外消耗 CPU 的时间,不适宜于信息量大或操作频繁的场合
线程
线程之间私有和共享的资源
- 私有:线程栈,寄存器,程序计数器
- 共享:堆,地址空间,全局变量,静态变量
进程和线程关系:
- 线程是轻量级进程(light-weight process),也有PCB,创建线程使用的底层函数和进程一样,都是clone
- 从内核里看进程和线程是一样的,都有各自不同的PCB。在Linux环境下线程的本质仍是进程。
- 进程可以蜕变成线程
- 在linux下,线程最是小的执行单位;进程是最小的分配资源单位
1 |
|
gdb调试多线程
1 | thread info |
线程间通信/同步
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制
互斥锁 Mutex
读写锁 pthread_rwlock_init/destroy/rdlock/wrlock/unlock
自旋锁
条件变量 pthread_cond_init/destroy/wait/signal
可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
信号量 sem_init/destroy/wait/post
可以用来控制多个线程对共享资源的访问,但信号量有限
PV 原语是对信号量的操作,一次 P 操作使信号量减1,一次 V 操作使信号量加1。
信号量主要用于进程或线程间的同步和互斥这两种典型情况。
信号量数据类型为:sem_t。
单线程、多线程比较
| 项目 | 单线程 | 多线程 |
|---|---|---|
| 编程、调试 | 编程简单,调试简单 | 编程复杂,调试复杂 |
| 可靠性 | 取决于这一个线程 | 一个线程挂掉将导致整个进程挂掉 |
| 内存、CPU |
生产者消费者模型-条件变量
1 | // 节点结构 |