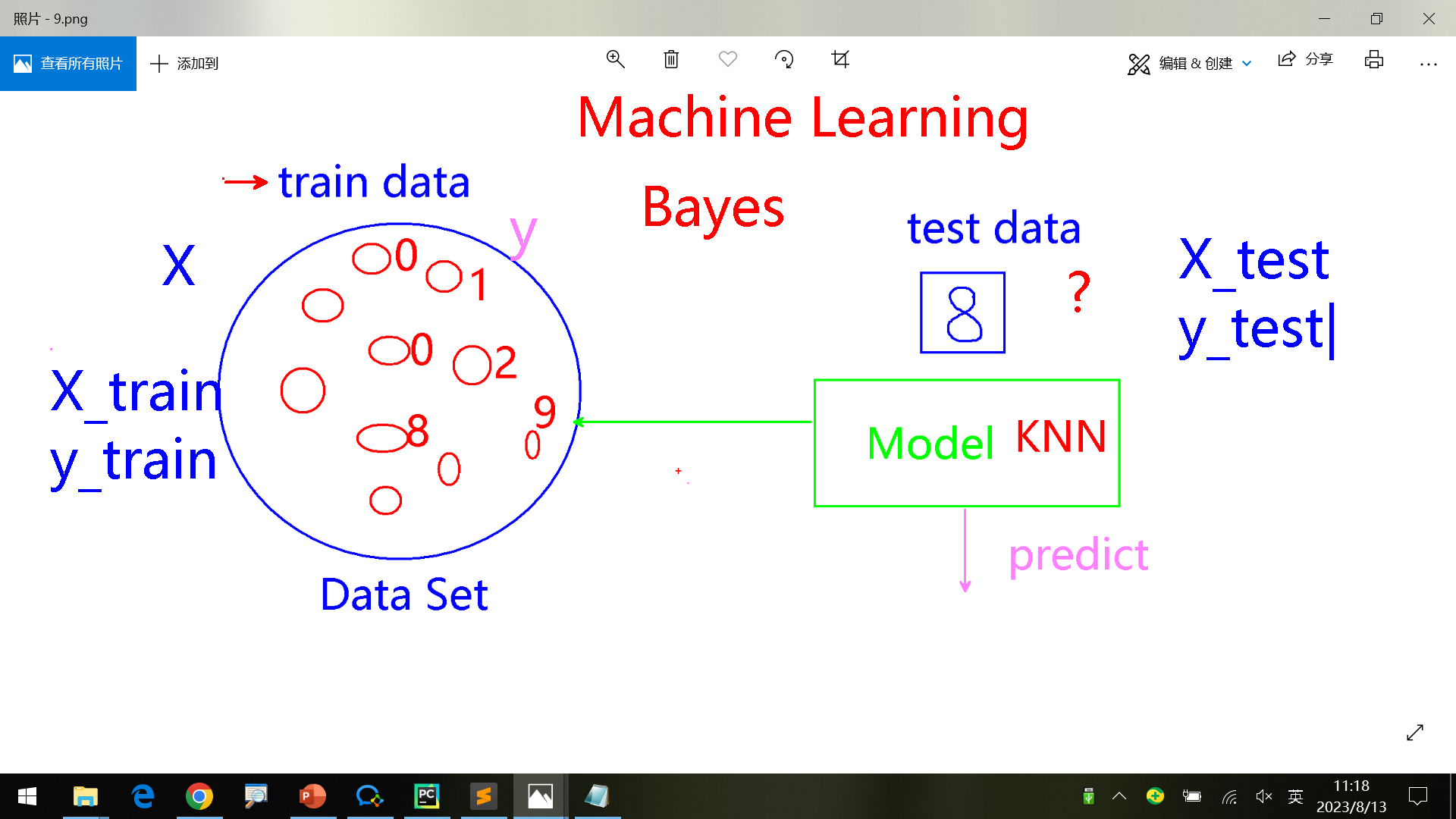
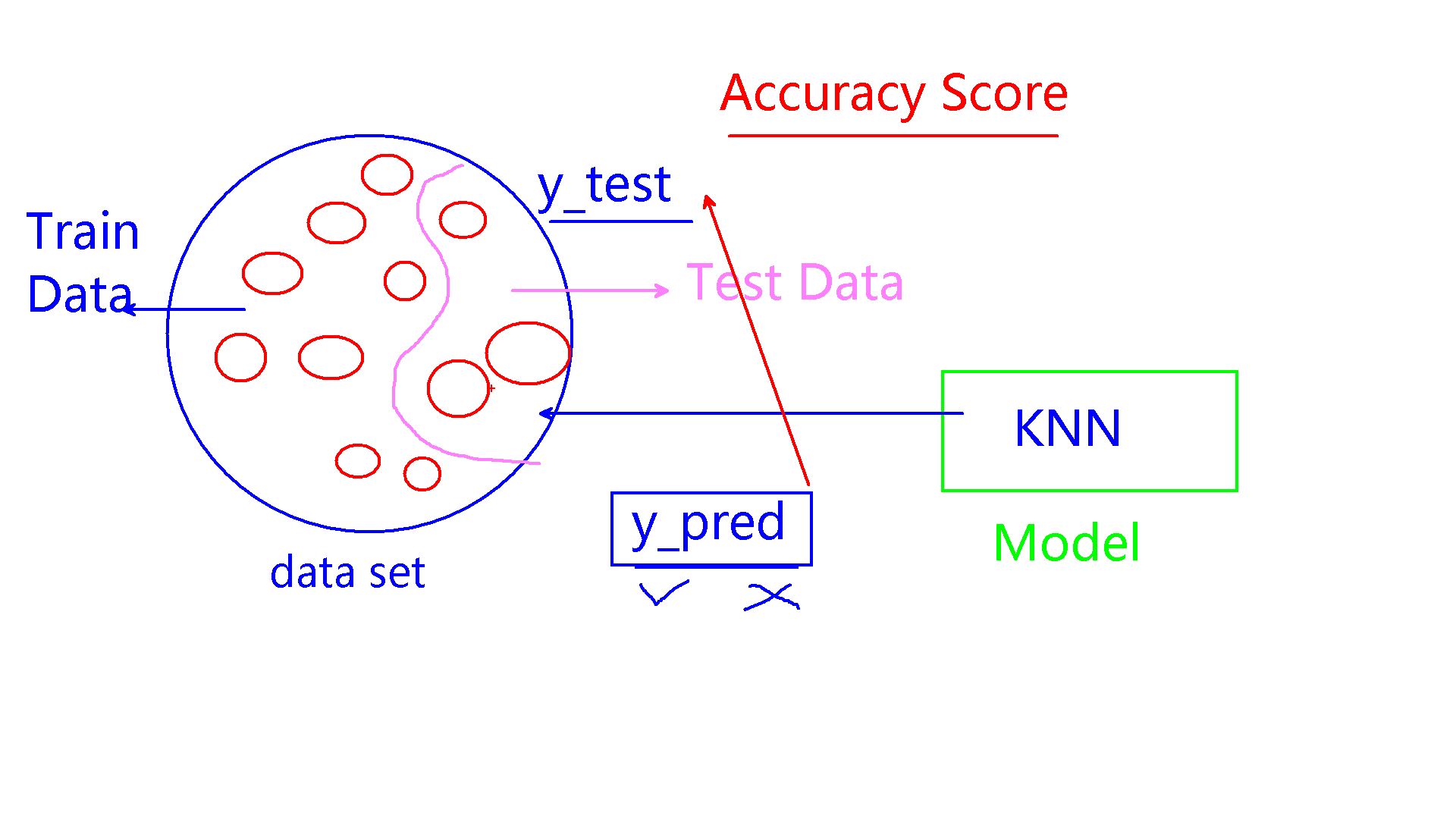
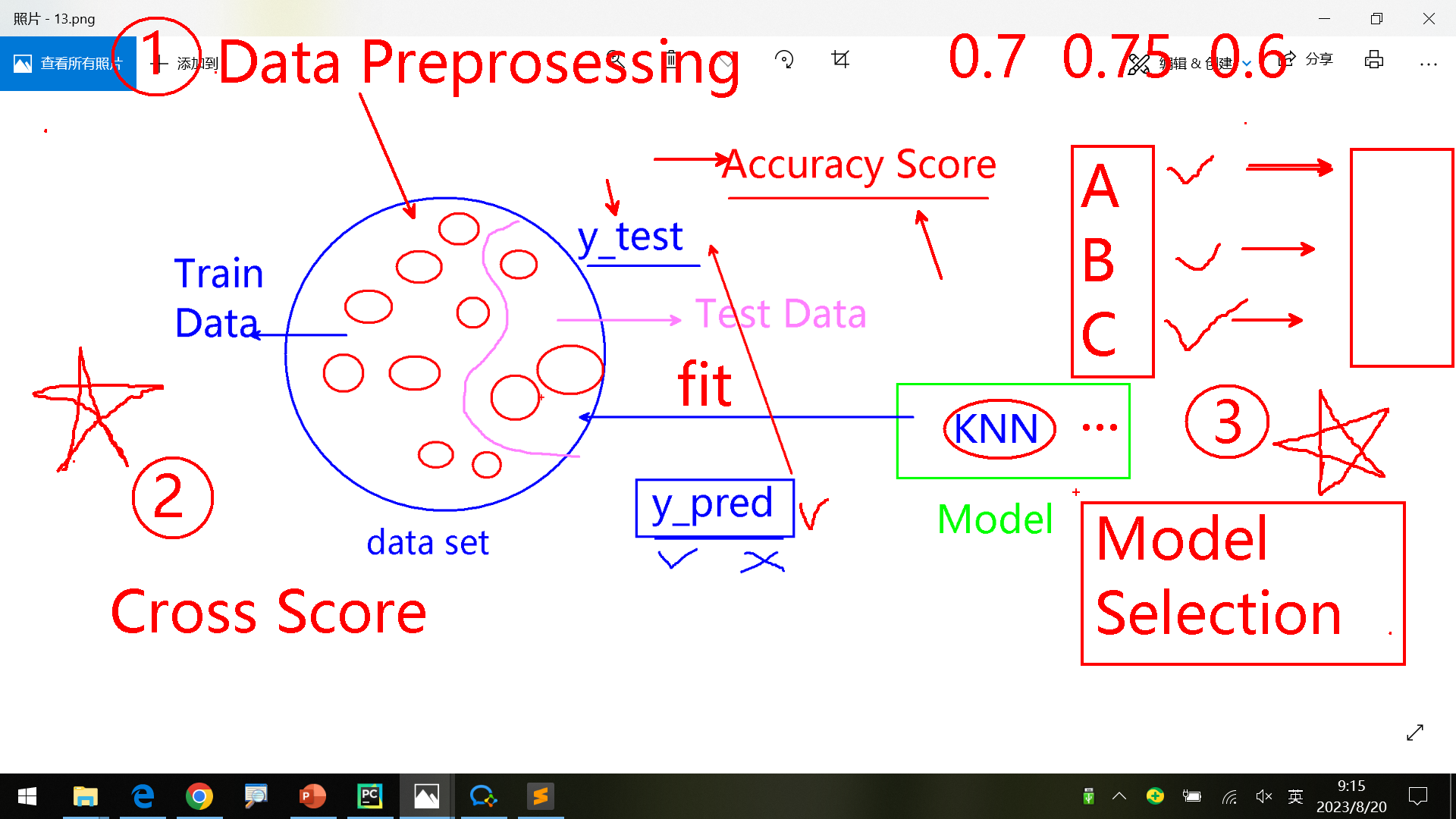
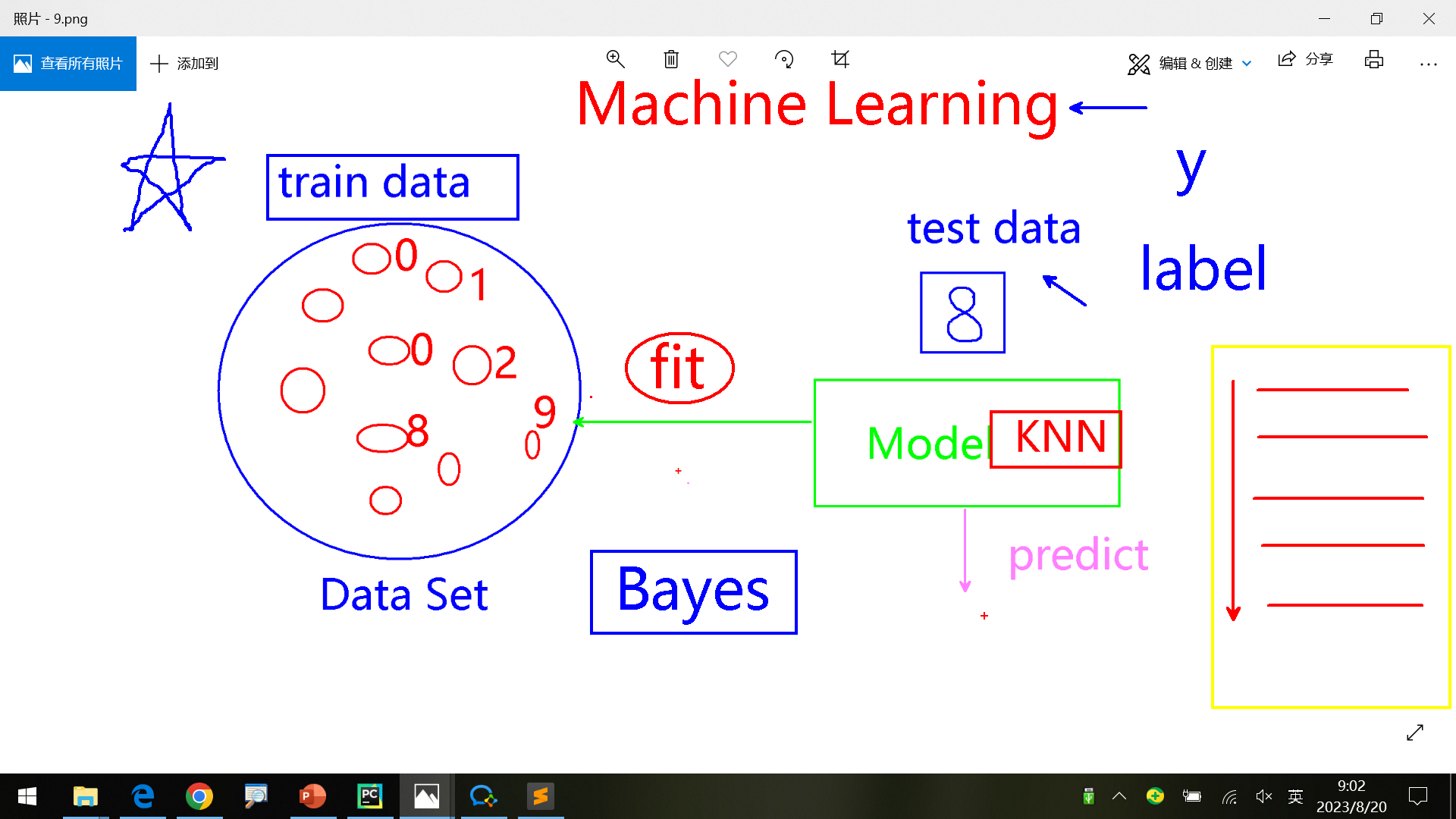
复习 预测模型
评估模型 对多个模型进行选择,基于准确率accuracy score进行。
其他
都是基于概率论的贝叶斯公式bayes‘ rule。
主干工作是前面的2个模型,后期的工作是研究各个算法 (课堂只用了KNN等),拓宽广度为工作服务,但暂时先不必研究深度,后期如果研究透了再研究。
学者一般是只研究理论,而不实践应用。
在不疑处有疑。 在别人不怀疑的地方怀疑
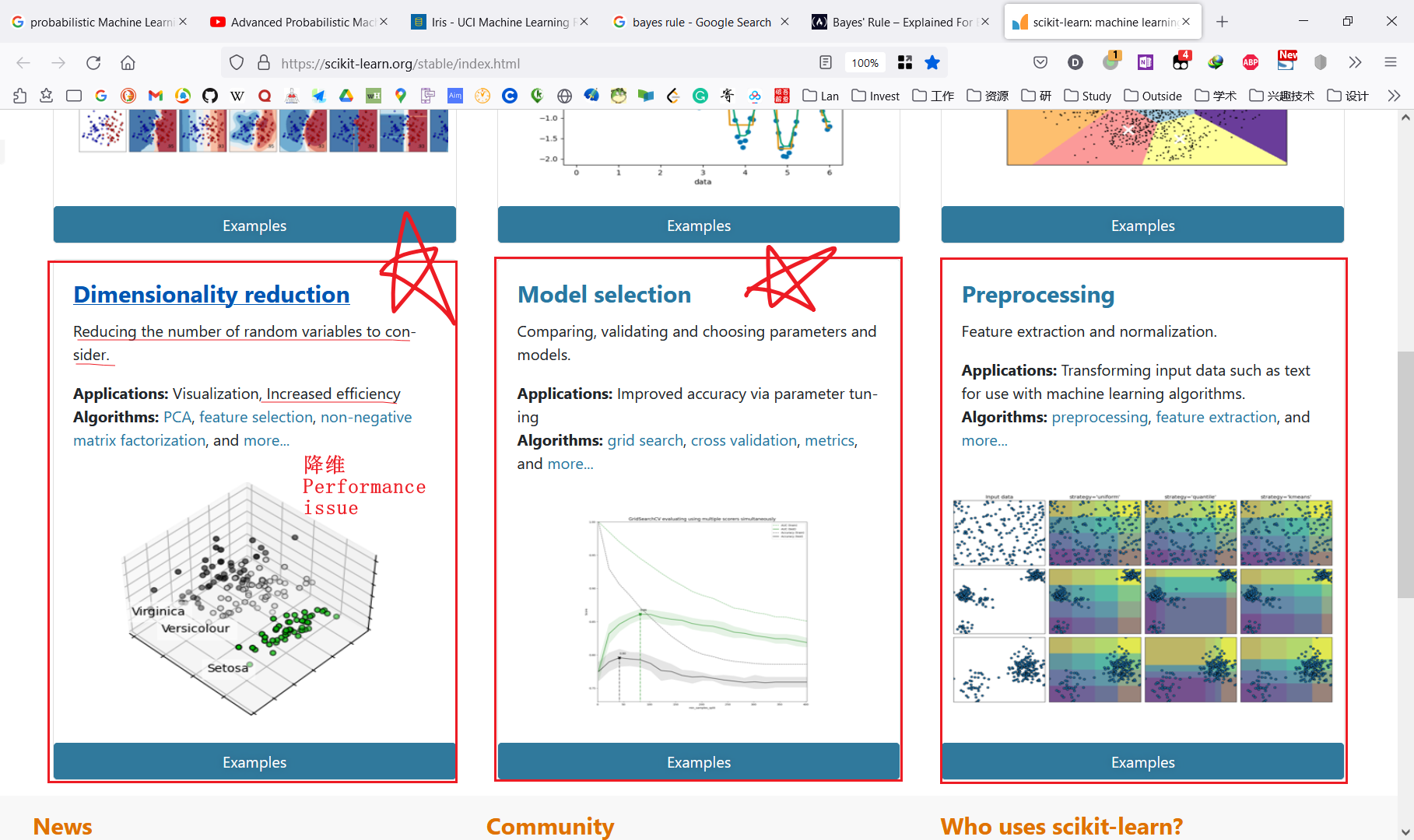
本节预览Data preprosessing、Model Selection(对评估模型优化) 这节课程主要是这3部分,重点是2和3。
Data preprosessing数据预处理,类似数据清洗。
交叉评估模型Model Selection
如何根据客户数据对算法进行选择(这部分最耗时,也是实际工作中的主要内容;其他classification, regression, clustering里的具体算法都是工具箱的工具)。实际工作中算法主要是为了优化,根据算法本身手动实现的代码,而不是采用库中的标准教科书算法。
Preprocessing数据预处理和Dimensionality reduction降维处理 比较类似。
Preprosessing 因为算法对数据有要求,所以只针对数据部分x进行处理,不改变结果y(target)
Rescale 缩放
Standardize 标准化
Normalize 规范化
Binarize 二进制化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import pandas as pd from sklearn.preprocessing import MinMaxScaler from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import Normalizer from sklearn.preprocessing import Binarizer import numpy as np data_set = pd.read_csv("pima-indians-diabetes.csv" ) feature_columns = ['pregnant' , 'glucose' , 'bp' , 'skin' , 'insulin' , 'bmi' , 'pedigree' , 'age' ] X = data_set[feature_columns] y = data_set.label mms = MinMaxScaler() X_rescaled = mms.fit_transform(X,y) np.set_printoptions(precision=3 ) print (X_rescaled) ss = StandardScaler() X_rescaled = ss.fit_transform(X,y) print (X_rescaled) nl = Normalizer() X_rescaled = nl.fit_transform(X,y) print (X_rescaled) b = Binarizer() X_rescaled = b.fit_transform(X) print (X_rescaled)
实例1-Predict-lg算法 上一节课使用了决策树算法,判断糖尿病。这次尝试使用logistic regression 算法。
python中如何判断算法属于哪种分类?
1 2 3 4 5 6 7 8 9 10 11 12 import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression data_set = pd.read_csv("../pima-indians-diabetes.csv" ) feature_columns = ['pregnant' , 'glucose' , 'bp' , 'skin' , 'insulin' , 'bmi' , 'pedigree' , 'age' ] X = data_set[feature_columns] y = data_set.label lr = LogisticRegression() lr.fit(X,y)
直接使用会报错
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.Increase the number of iterations (max_iter) or scale the data as shown in:https://scikit-learn.org/stable/modules/preprocessing.html
2种方案:增加迭代次数或者scale缩放数据。
…
带团队时,一定要一开始定好规范,比如注释等,后面会很容易。
方案1:
1 lr = LogisticRegression(max_iter=200 )
方案2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import MinMaxScaler data_set = pd.read_csv("../pima-indians-diabetes.csv" ) feature_columns = ['pregnant' , 'glucose' , 'bp' , 'skin' , 'insulin' , 'bmi' , 'pedigree' , 'age' ] X = data_set[feature_columns] y = data_set.label mms = MinMaxScaler() X_rescaled = mms.fit_transform(X) lr = LogisticRegression() lr.fit(X_rescaled,y)
添加测试数据,进行预测。最终结果如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import MinMaxScaler data_set = pd.read_csv("../pima-indians-diabetes.csv" ) feature_columns = ['pregnant' , 'glucose' , 'bp' , 'skin' , 'insulin' , 'bmi' , 'pedigree' , 'age' ] X = data_set[feature_columns] y = data_set.label mms = MinMaxScaler() X_rescaled = mms.fit_transform(X) lr = LogisticRegression() lr.fit(X_rescaled,y) test_data = [7 , 196 , 90 , 0 , 0 , 39.8 , 0.451 , 41 ] y_pred = lr.predict(np.array(test_data).reshape(1 ,-1 )) print (y_pred)
输出:
[1]
表示患有糖尿病
实例2-Model Selection-lg算法 类似前面的,使用logistic regression 算法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score data_set = pd.read_csv("../pima-indians-diabetes.csv" ) feature_columns = ['pregnant' , 'glucose' , 'bp' , 'skin' , 'insulin' , 'bmi' , 'pedigree' , 'age' ] X = data_set[feature_columns] y = data_set.label X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25 ) lr = LogisticRegression() lr.fit(X_train.values,y_train.values) y_pred = lr.predict(np.array(X_test)) print (accuracy_score(y_test,y_pred))
结果发现仍然有之前的报错:
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:https://scikit-learn.org/stable/modules/preprocessing.html
方案1:
1 2 lr = LogisticRegression(max_iter=200 ) lr.fit(X_train.values,y_train.values)
输出结果
0.64
方案2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score data_set = pd.read_csv("../pima-indians-diabetes.csv" ) feature_columns = ['pregnant' , 'glucose' , 'bp' , 'skin' , 'insulin' , 'bmi' , 'pedigree' , 'age' ] X = data_set[feature_columns] y = data_set.label X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25 ) mms = MinMaxScaler() X_train_rescaled = mms.fit_transform(X_train) lr = LogisticRegression() lr.fit(X_train_rescaled,y_train) y_pred = lr.predict(np.array(X_test)) print (accuracy_score(y_test,y_pred))
输出结果
0.36
结论* 可以看出,2种方案结果差异很大。
实际上经常会发现,同样的数据,不同的算法会有不同的效果 。数据和算法要匹配才能取得最佳效果。(这里的是医疗数据,KMeans算法最合适;上周的手写数字的数据在KNN算法下最优。)
其次,需要进行模型优化 :
取平均值思路
测试集质量思路
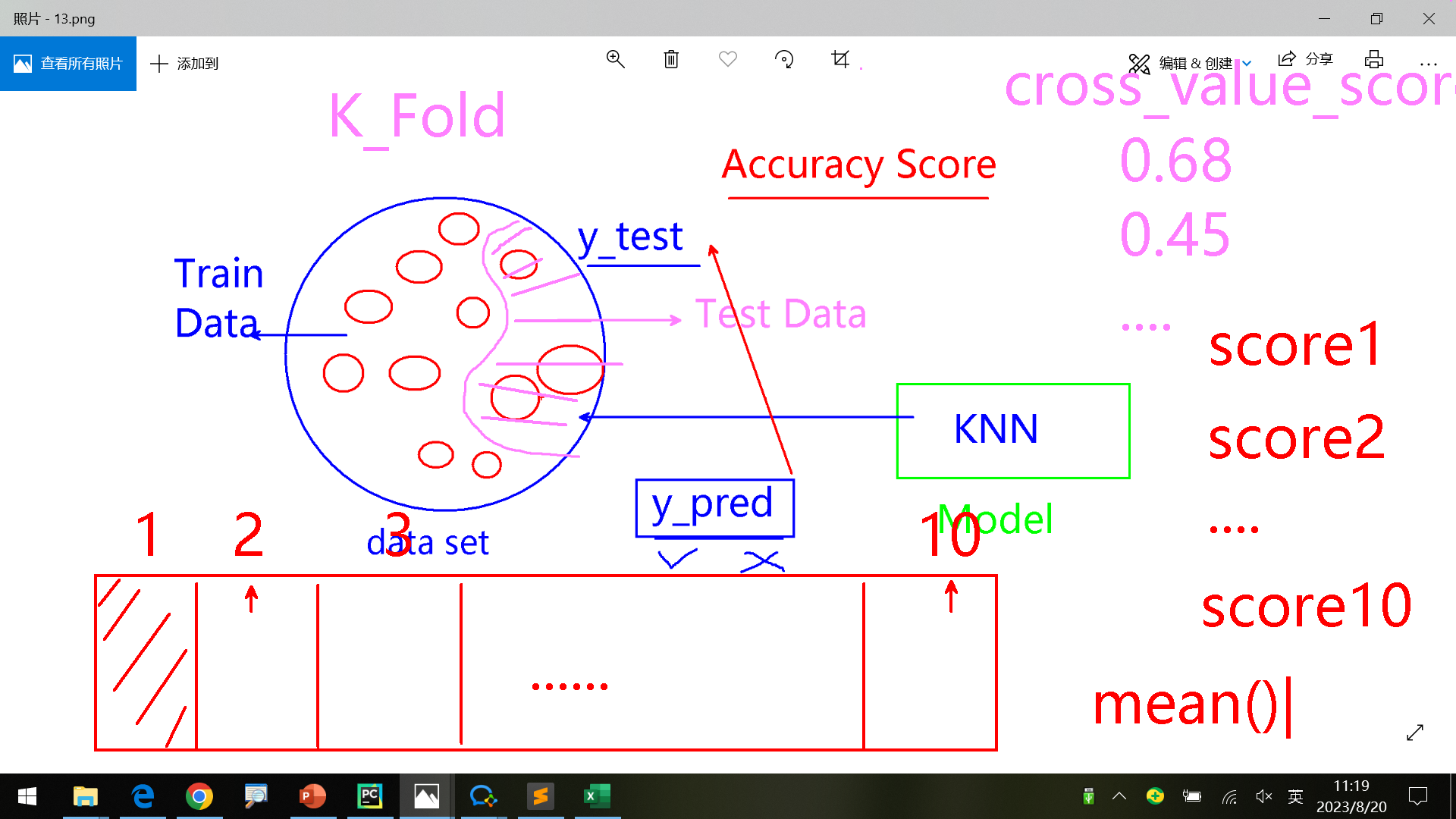
模型优化-KFold 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import pandas as pd import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score data_set = pd.read_csv("../pima-indians-diabetes.csv" ) feature_columns = ['pregnant' , 'glucose' , 'bp' , 'skin' , 'insulin' , 'bmi' , 'pedigree' , 'age' ] X = data_set[feature_columns] y = data_set.label mms = MinMaxScaler() X_rescaled = mms.fit_transform(X) kf = KFold(n_splits=10 ) lr = LogisticRegression() cv_results = cross_val_score(lr, X_rescaled, y, cv=kf) print (cv_results) print ("mean: %.2f var: %.2f std: %.2f" % (cv_results.mean(), cv_results.var(), cv_results.std()) )
输出结果:
[0.6 0.4 0.6 0.6 0.8 0.8 0.7 0.8 0.8 0.7]
最后一行输出中,平均值为最终结果(越大越好),var和std是方差和标准差,用于评估准确率的稳定性(越小越好)
即使是这样,也可能不够好。比如取样的时候某一测试集结果值y都为1(其他数据都作为训练集),这样取值不均匀,不够好。
优化思路:
每次fold之前根据y值进行“洗牌”,将标签值打乱,确保fold后每组取值均匀。
每轮一次fold,多次重复计算,N-Repeated。
Model Selection 使用同一组数据 对不同算法 分别进行评估,最后根据结果选择出最适配的算法。
因为前面KFold算法只是随机选取,可能因为一组中label值不够均匀导致偏差较大,因此更换为增强版KFold算法StratifiedKFold。
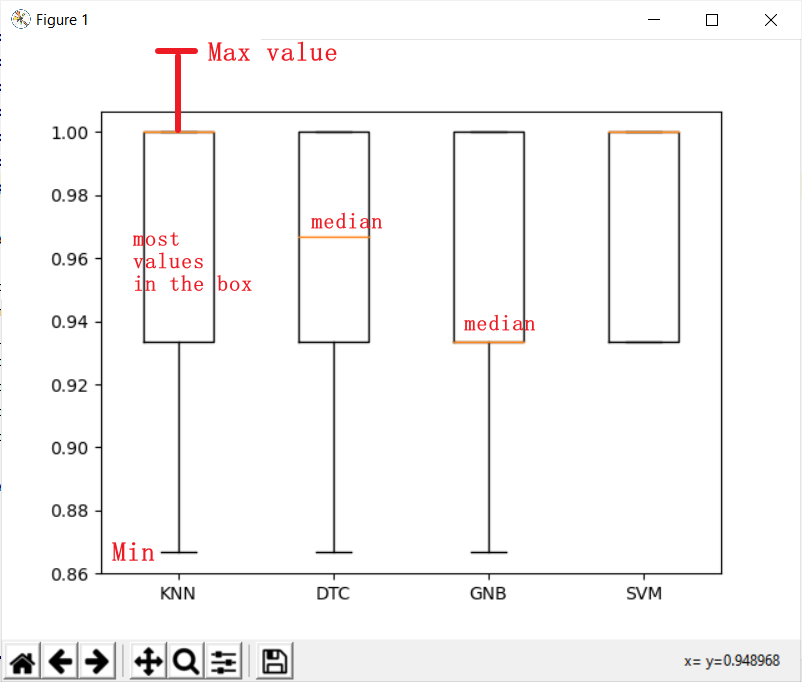
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from sklearn import datasets from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC from sklearn.model_selection import StratifiedKFold from sklearn.model_selection import cross_val_score X,y = datasets.load_iris(return_X_y=True ) models = [] names = [] cv_results = [] models.append(("KNN" , KNeighborsClassifier())) models.append(("DTC" , DecisionTreeClassifier())) models.append(("GNB" , GaussianNB())) models.append(("SVM" , SVC())) for name, model in models: skfold = StratifiedKFold(n_splits=10 ) cv_score = cross_val_score(model, X, y, cv=skfold, scoring='accuracy' ) cv_results.append(cv_score) names.append(name) print ("%s: %f %.3f %.4f" % (name, cv_score.mean(), cv_score.std(), cv_score.var()))
输出如下:
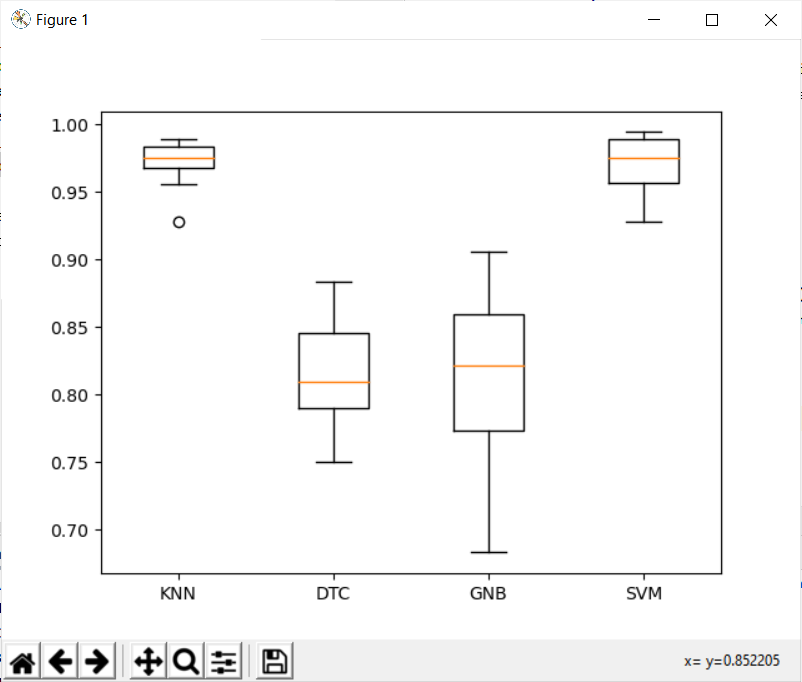
1 2 3 4 KNN: 0.966667 0.045 0.0020 DTC: 0.953333 0.043 0.0018 GNB: 0.953333 0.043 0.0018 SVM: 0.973333 0.033 0.0011
第一列为均值(看这个评估准确率,越大越好),第二、三列为标准差(看这个评估稳定性,越小越好)、方差(仅供参考)。
为了便于观察计算结果,导入matplotlib.pyplot包,在最后添加下面的代码画出箱子图。
1 2 plt.boxplot(cv_results,labels =names) plt.show()
输出图形:
更换数据 把数据改为数字识别数据
1 X,y = datasets.load_digits(return_X_y=True )
结果发现KNN效果最好。KNN算法太慢 ,因为:
每次必须等到test data过来才能计算。
每次计算要使用这一个test data 遍历它到train data中每个data 的距离。根据test data到所有train data的距离,找到train data中最匹配的data,取它的label作为y_pred。
优化方案是:
Confusion Matrix 前面iris的图中,假如有一个算法的boxplot和SVM算法一样时如何解决?
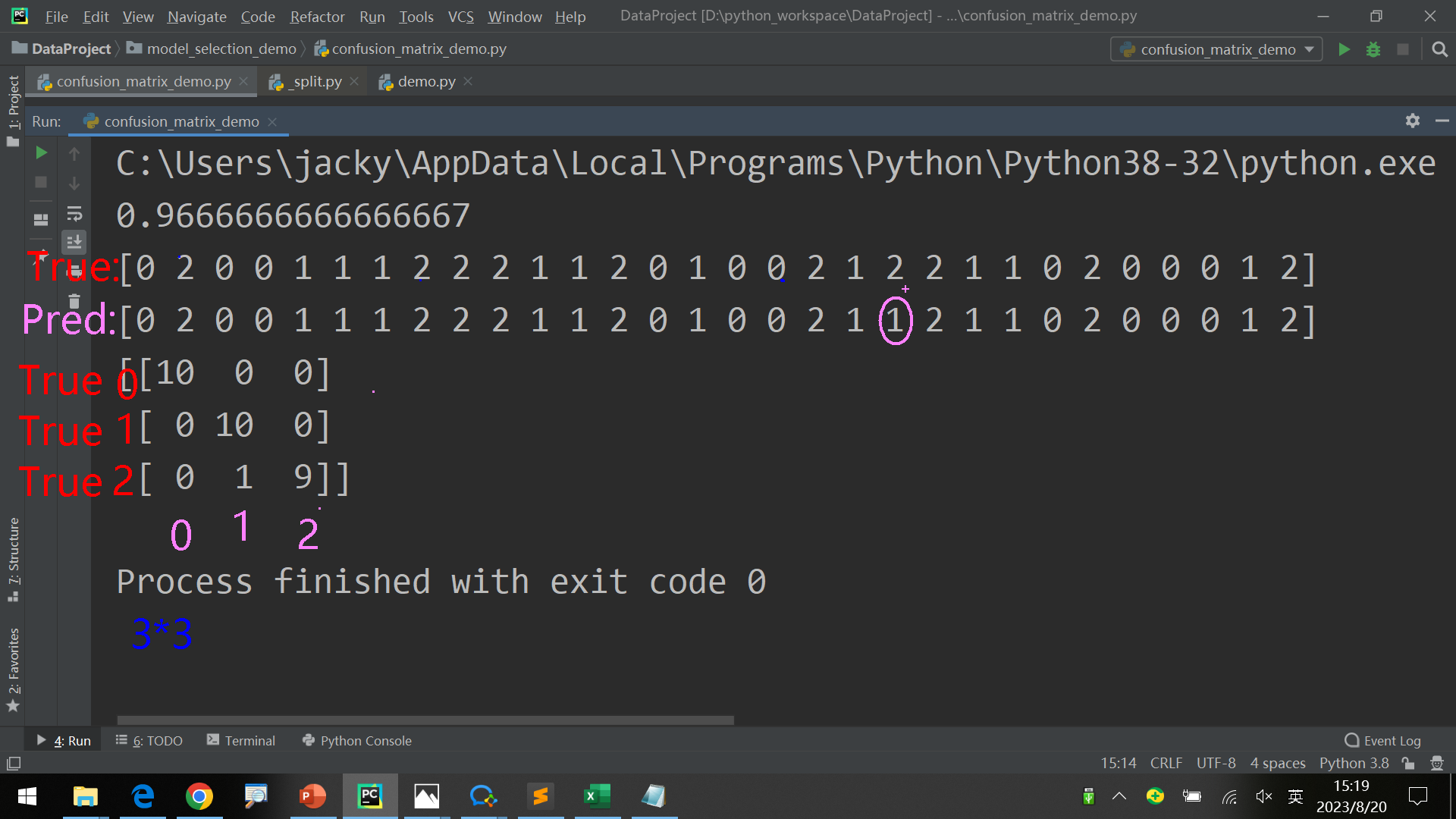
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from sklearn.datasets import load_iris from sklearn.svm import SVC from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.metrics import confusion_matrix X,y = load_iris(return_X_y=True ) X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.25 ) svm = SVC() svm.fit(X_train, y_train) y_pred = svm.predict(X_test) print (accuracy_score(y_test, y_pred)) print (y_test) print (y_pred) print (confusion_matrix(y_test, y_pred))
输出结果:
0.9736842105263158
有时候结果完全正确,此时得到的confusion_matrix是对角矩阵:
1.0
因为label的取值有3种0,1,2,因此得到3*3矩阵。如果是2种取值,则是2*2矩阵。
对于第i列,每一列的数据和是正确结果为i 的个数
对于第i列,每一列的数据和是实际结果为i 的个数
图中:
一般来讲,执行到计算平均值、方差、标准差就可以了,计算Confusion Matrix属于进阶操作。
具体Confusion Matrix的用处?
为什么以及如何学机器学习
学习路径:https://scikit-learn.org/stable/index.html
数据分析方向基础能力 主要是3种能力:
具体来说,课后这个方向要做的是:
研究各个算法(课堂只用了KNN等)具体干了些什么,而不只是使用。拓宽广度为工作服务,但暂时先不必研究深度,后期如果研究透了再研究。
学习过程中多看ML相关英文资料。
目前(2023.8)来说,国内机器学习方面主要是大厂招人做研究,更偏向学术一点,因此岗位很少,而且要求很高。但是美国已经开始了这样的应用,目前国内的发展进程大概是美国10年前的样子。按照美国的发展经验,后面再过几年(5年?)也会开始大规模应用,到时候相关岗位会很多,而且也不会要求这么高。